Supporting Schema Evolution and Addition in Fineo
May 15, 2017 - San Francisco, CAFineo’s architecture is designed to help people go faster, while having to do less by leveraging our NextSQL system. At the surface, it’s not that much different from the the Lambda Architecture - a realtime serving layer and an offline batch processing step to reorganize data for offline analytics. However, we apply some “magic” to gracefully manage schema and provide a single interface for fast answers to realtime and offline queries.
In one of my very early posts about Fineo I talked about how users had one month for formalize schema or some data would be lost. But that kind of sucks - you should never have to get rid of data.
So, I spent some time digging into the particulars of our query execution engine (Apache Drill) and our batch processing engine (Apache Spark) to enable reading data against typed columnar rows and schema-less JSON based rows.
The batch processing step looks like this:
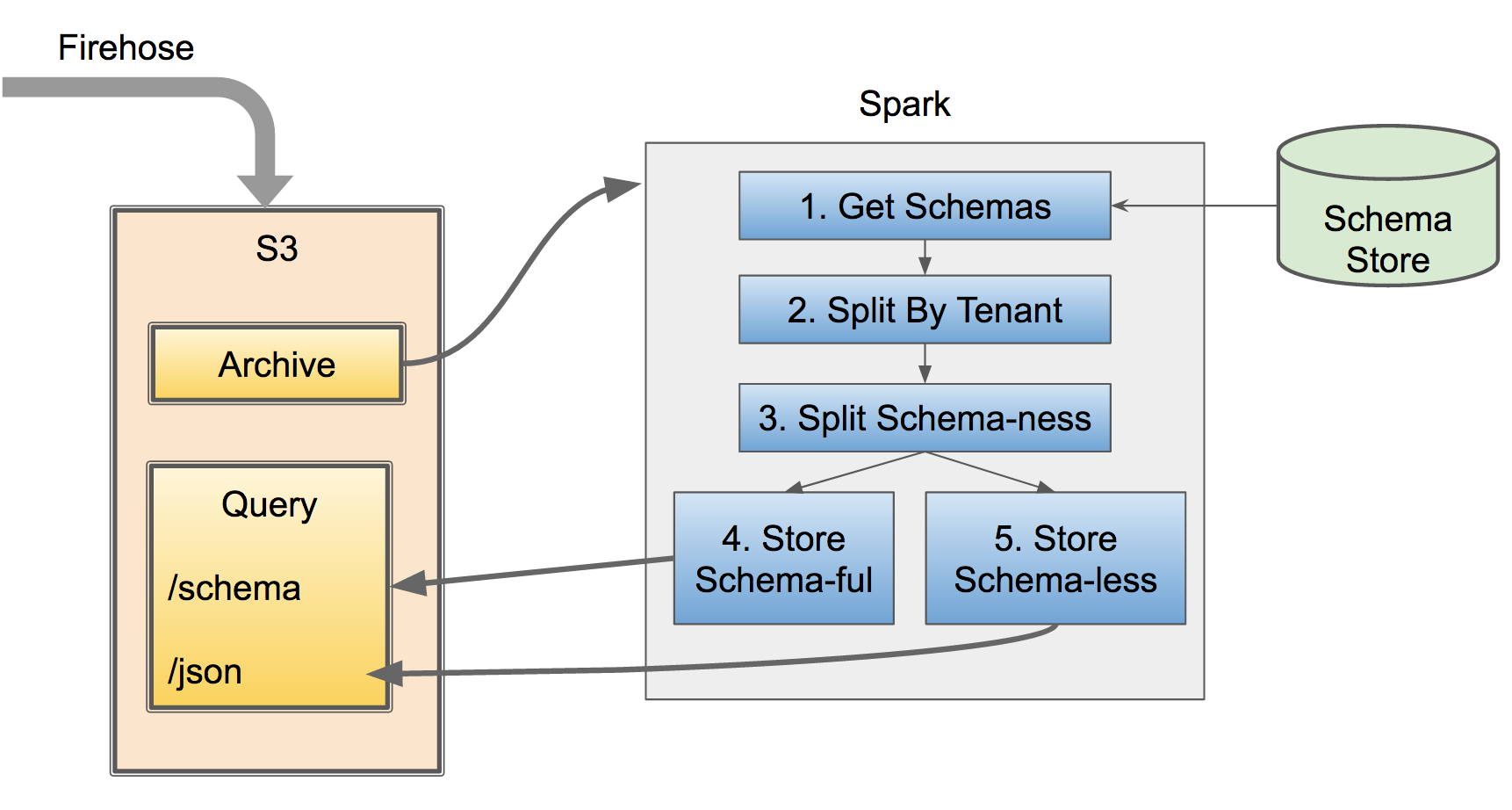
- Get all the data from periodic S3 dumps from the ingest pipeline (orchestrated by Amazon Firehose)
- Get all the known schemas for possible tenants
- Group by tenant
- Sub-group by schema-less and schema-ful
- Apply schema to known rows
- Write each group to own keyed directory hierarchy
Schema-ful rows can be written in an optimized, columnar format that is highly suitable to analytics. The schema-less columns (columns for which we have data, but no official schema) still need to be readable, but cannot necessarily be optimized because we don’t know its type; here we default to just storing the data in raw JSON format. Both types of data still require a timestamp and are partitioned based on that timestamp to enable quick point and range lookups across a time range.
Schema-ful Rows
The schema-ful data are those columns of rows that have a known name. Internally, once a column is ‘schema-fied’ it gets a ‘canonical name’ that we use across the platform. However, we still store data based on the incoming data name as it allows users to have more granular, on-demand history. Thus, a query for a column is a one-to-many lookup of column name -> canonical name -> column ‘aliases’ (or all the possible names for the column), which is internally used to generate the query.
Since we know the ‘type’ of each column/field in each event, we can store them in format suitable to analytics. We chose Apache Parquet) as a fast, easy to use and widely integrated columnar format. We then further optimized by lookups by storing all events in a directory hierarchy suitable for time-series queries, something like:
/tenant id
/metric
/year
/month
/day
Unfortunately, there is not a lot of interoperability support between Apache Spark (batch processing engine) and Apache Drill (read engine). This means that writing partitioned data with Spark will not be readable by Apache Drill (this is because Spark writes partitions as key=value and Drill reads partitions as a nested hierarchy of value1,value2, etc.). That means we also have to extract the components of the timestamp and into the sub-partitions we want, construct those directories manually and write the Parquet data into the output directory.
Basically, we manually create the time-based partitioning. A bit hacky, but it works.
Schema-less Columns
Each well-formatted row is bound to a specific ‘metric type’ (think user-visible table), but schema-less columns are those columns but have not been formally added to the schema. We know the event is bound to a particular metric type (its required to be a valid row), but we don’t know how that field fits in with the schema - what is its type, is it an alias of an existing column?
These kinds of fields occur when you have changing data and don’t update the schema, either out of laziness or from a misspelling (e.g. a ‘fat finger’ mistake). In many systems, this unknown column will be a surprise and can either break your pipeline or get thrown out - bad outcomes either way. Generally, this requires going upstream to fix the mistake at the source (often painful and takes a long time), or requires lots of special casing code in your ETL codebase.
Fineo is built to handle this sort of change gracefully and without interruption.
These schema-less columns are grouped together in the batch processing step and written out to their own tenant-grouped, time-partitioned sub-directory:
/json
/tenant id
/metric
/year
/month
/day
There is a slight trick with JSON storage that binary data needs to be base64 encoded to support storage as JSON and then auto-translated back in the read pipeline. Not terribly efficient, but it then works for all data types (oh, the joys of platform!).
This allows us to easily query either the JSON and/or Parquet formated data. At the same time, we can also periodically re-process the JSON data when there is a schema change to generate the columnar format, significantly speeding up access to that data. There is a bit of fiddling to ensure that the switch is atomic (or near enough), but that is left as an exercise to the reader.
Summary
Moving data to an offline, columnar storage allows us to efficiently support analytics queries. At the same ‘time’, time-partitioning allows fast answers on a very wide range of events because we can quickly pinpoint the range of data to access. But you can get that with a ton of existing systems (Hive, Kudu, etc.). The magic lies in how to support a fast-changing enterprise and dataset with features like column aliasing and renaming, and late/async-binding schema, so you can go faster, while doing less.
Want to learn more about the Fineo architecture? Check out the next post in the series: Error Handling and User Notification.
-----------
Like this sort of stuff? Consider subscribing to the RSS feed.
blog comments powered by Disqus