Handling Errors in Fineo
May 17, 2017 - San Francisco, CAPassing pipeline processing errors back to the user was not originally built into the Fineo platform (a big oversight). However, we managed to add support for it over only a couple of weeks. Moreover, we were able to make it feel basically seamless with the existing platform.
When writing to Fineo, you can get an error if the ingest buffer is temporarily full. However, you may have written a bad event and that won’t be detected until the event is processed a short time later. These errors can be seen in a special errors.stream table, but don’t touch any part of the ‘core’ data storage layers.
The overall Fineo platform looks like this:

Capturing Errors
An error can occur at each stage in the event processing pipeline (currently only two parts: raw and staged). The event, context and error messages are captured and sent to a special AWS Firehose, while the event is marked ‘successfully processed’ in the parent buffer (avoiding attempted reprocessing).
Firehose will periodically export data to an S3 bucket, partitioned by year, month, day and hour.
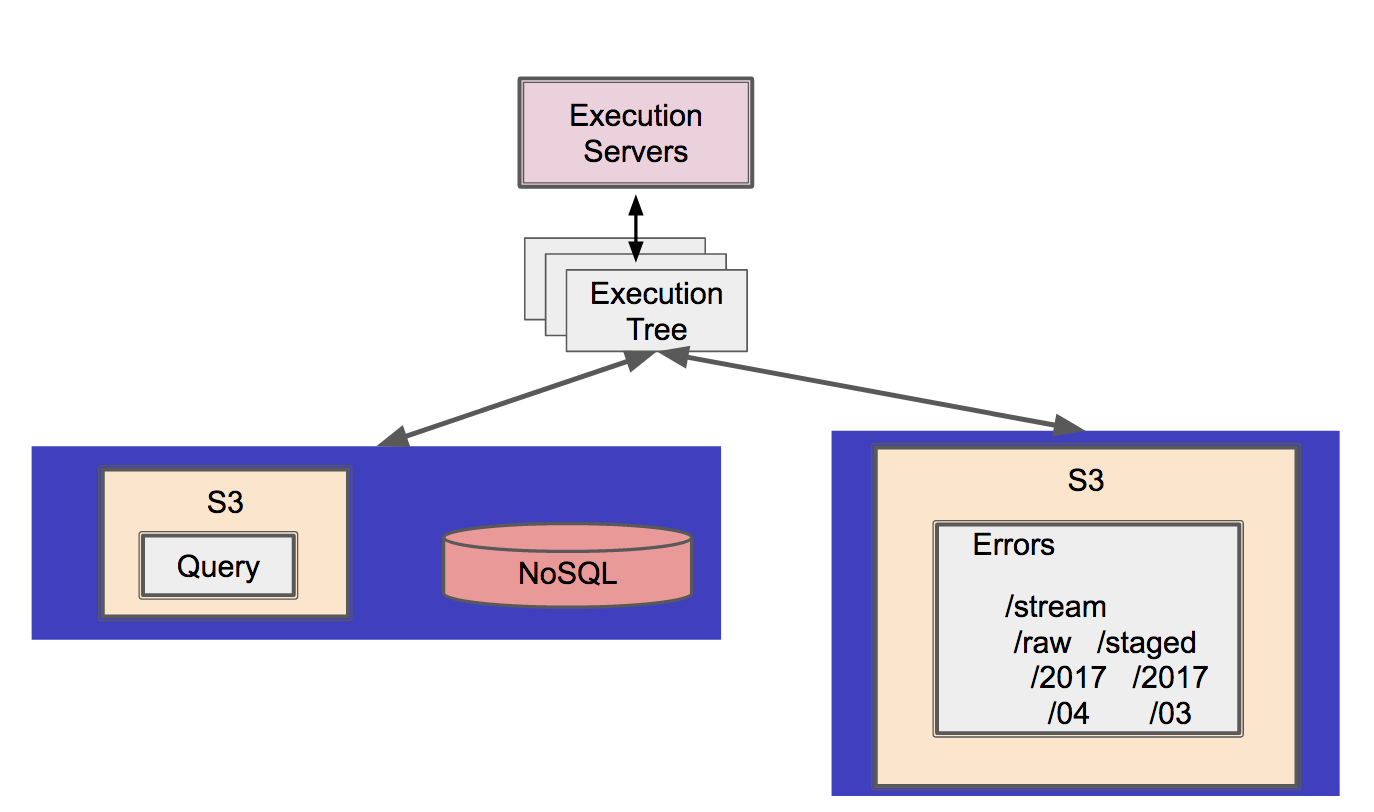
When evaluating possible options for serving this data to users - AWS Athena, ElasticSearch - I decided to serve it back through the main Fineo API and query engine. That meant extending the core to support this new data source, but was already had a SQL query engine that supported a partitioned, S3 storage mechanism; it seemed a lot easier that standing up a new service and learning a new set of infrastructure (and securing that too!).
Reading Errors
In the ‘regular’ Fineo infrastructure, the Tenant Key is part of the directory hierarchy. However, using Firehose for error capture meant that now the only place the Tenant Key is stored is the event itself.
Our errors.stream table can only point to a generic S3 ‘errors’ directory, requiring the Tenant Key to be filtered out of the event itself (ensuring tenants cannot access other tenants’ errors). This ended up being only a slight shift in how we were already managing queries as the tenant key was already being surfaced as projected field from every event on read. Thus, it came down to be only a relatively simple matter of some query translation and data source redirection.
Queries get translated quite simply.
> SELECT * FROM errors.stream
turns into
> SELECT * FROM errors.stream WHERE api_key = 'the_user_api_key'
for all requests.
Fineo uses Apache Drill under the hood, which natively supports reading JSON. It has the caveat that the JSON elements must not be comma-separated, but that actually works to our advantage as we don’t need to worry about separating error events when sending them to Firehose. Drill also supports directory-based partitioning, allowing us to very efficiently zero in on a user’s requested search time-range.
We then can easily read JSON data with the S3 storage engine with a hierarchy like:
/errors
/stream
/raw <-- 'raw' stream processing stage
/malformed <-- the type of error in the stage
/commit
/year
/month
/day
/hour
some-firehose-dump.json.gz
/storage <-- 'storage' stream processing stage
...
and quickly zero in on the type of error or when it occurred, and can surface those as fields in the error event row.
| Timestamp | Stage | Type | Message | Event |
|---|---|---|---|---|
| 149504314500 | raw | malformed | Event missing timestamp | {“metrictype”: “metric”, “value”: 1} |
| 149504314502 | staged | commit | Underlying server rate exceeded. Retrying. | {“metrictype”: “metric”, “value”: 1, “timestamp”: 149504314502} |
The ‘zoomed in’ view of the error query architecture then looks like:
Informing Users
Now that we had a way to surface the errors, the question arose of how to make it easy for users to get that information. Yes, they could query the errors.stream table in a SQL tool, but that kind of sucks (it creates a lot of friction).
The last bit of work came in adding support for the error table to the Fineo Web App - a simple UI for users to view any errors they had.
While we support simple SQL queries sent to a REST endpoint, I didn’t want to overwhelm the web server with lots of requests or paging. However, because of the nature of reading errors is inherently sequential in time, I could easily page through the results based on the last received time stamp and the request error time range. This meant we didn’t have to leave open a socket connection or cursor in the database.
Summary
When you have a hammer, everything looks like a nail, but sometimes they actually are nails. With Fineo error management, we had a very clean integration with our existing infrastructure that let us implement a complete error analysis solution in under two weeks, from inception to deployment. And best of all? It fit well within our current user’s mental model and solved their issues.
Want to learn more about the Fineo architecture? Check out the next post in the series: Building a Continuous Integration Pipeline with Jenkins on AWS.
-----------
Like this sort of stuff? Consider subscribing to the RSS feed.
blog comments powered by Disqus