Dynamic, Lazy Schema at Scale
March 09, 2016 - San Francisco, CASchema management is some of the most painful database work and anything you can do to make it easier can dramatically reduce an enterprises’ iteration interval. At Fineo we are focused on delivering a scalable, enterprise grade time-series platform. While we do lots of the expected enterprise-y things - backups, end-to-end security, audting, etc - and some things enable us to iterate quickly (like in my Fineo ingest pipeline post). However, today I’m going to talk about how we enable customers to have completely dynamic and lazy schema.
Dynanic, lazy schema means that at any point you can:
- change the names of fields
- group multiple physical names into a single field
- query data before you have defined the schema
When it does come time to formalize your schema (up to a month after data has been written), Fineo will make suggestions about what type we think the data is and if it might actually just be an alias for another logical type, all based around the queries you have made on the un-schema’d data.
Lets take a look at an example where dynamic, lazy schema can be really useful.
Data Production Inc.
Suppose you work at Data Production Inc. (DPI) and are tasked with onboarding a new production line. You have a lot of machines to connect and then want to quicly analyze how the line is running so you can tweak it quickly. Then lets suppose you have a couple manufacturors of the same type of machine in your line - each has a slightly different name for the same kind of metrics, some metrics are from one machine and not in another.
In the traditional RDBMS world, this problem can be a huge pain all by itself. You have to figure out all the different possible fields you will receive. Then you need to manually write the mapping to an known name (normalizing field names), manage empty values and retest the pipeline multiple times until you are are sure you caught all the bugs.
Basically your standard, pain-in-the-ass ingest work. Only after you have done all of this massaging can you even begin to look at your line and determine how its running.

Fineo = Easy Ingest
With Fineo, you don’t have to do almost any of that work. In fact, once you point your machines at our ingest endpoints, we will automagically tell you all the different fields. From there, you can point-and-click your way to the schema you want. Field name normalizations (aliasing) is a simple drag-and-drop. Empty values are automatically handled by our NoSQL backend.
And then it gets really cool.
You don’t even need to do any of that schema management until you have time to get around to it. Instead, you can start querying for fields immediately, just by knowing the names and what type you expect it to be. From there, you can use the whole world of SQL to slice and dice data, so you can quickly and easily get your line running.
You have up to a month to formalize your schema. Formalizing the schema makes it so we can auto-complete queries (from the UI) and dramatically speed up any analytics. However, you can also continue using the alias names for different fields that you had developed before formalizing the schema, so the queries you are already running will continue to run just fine.
Schema Management Internals
In the Fineo ingest pipeline post, it looked like we only had one touch point with the schema store and that it was stand alone. That was a simplication of what it really looks like:
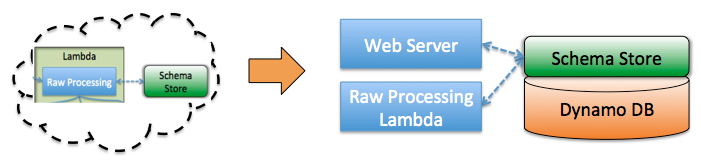
Ok, that really isn’t too much more, but those simple boxes hide a host of complexity.
Avro All Around
The root of our schema management process uses Apache Avro. Avro is great - it has schema evolution, field aliasing and self-describing serialization. Sounds like we are done! Just use Avro everywhere.
Not so fast.
To start with, you need a way to keep track of all different schemas for each customer. Enter the avro schema repo, based on some work Jay Kreps did in AVRO-1124. The Avro Schema Repo (ASR) is a REST-based service that lets you manage the evolution of schema for a logical ‘subject’, a collection of mutually compatible schemas (the changing schema of the ‘thing’ you are managing). The ASR comes with a couple of nice default database adapters - zookeeper and a local FS. If you poke around, there is also a JDBC-based backend.
At Fineo we try for ‘zero-ops’, choosing instead to rely on hosted services to get us running with minimum overhead and automating everything else. To that end, we wrote a custom schema store backend on top of DynamoDB. AWS also has relational database (RDS), but is managed by the machine, rather than by the request as with Dynamo, leading to more ops that we really wanted. The tradeoff with Dynamo is that we will incur 2-3x write overhead to ensure that we get consistent results [1].
We are already using Dynamo for our near-realtime store and it has nice NoSQL properties that let us really leverage dynamic field names, so it was a pretty easy choice. Fortunately, ASR has a pretty lightweight requirement on the database adapter and already has a caching strategy, so this was pretty easy to implement (especially using Dynamo’s simple ORM tools).
We hope to open source the DynamoDB adapter for ASR soon. Keep an eye out!
Avro Schema Repository Access
Continuing to zero-ops we can actually throw out the REST layer and just query DynamoDB directly using the ASR api[2. It still provides all the caching you would want, but saves us a network hop. Naturally, the trade-off is that we need to be very careful with how we evolve the schema and access patterns, but as a small shop with high visibility into the code effects, we made the choice to simplify ops over later complexity.
Keep in mind that the schema repository has two touch points, (1) the ingest pipeline, where we track new schema and apply existing schema to incoming events, and (2) the external-facing web server, which needs to understand schema to serve reads and for admins to manage the schema.
Since these are stateless services, we can deploy them as need be and even replace the direct DynamoDB access with the REST endpoint with minimal code changes (the client now talks to Also talking directly to our Dynamo endpoint gives us the ability to read and use previously unknown fields (discussed later).
Managing multiple entities
As a multi-tenant platform we naturally have to manage multiple customers. Each customer is assigned an Id - a tenantID (did you guess it?) - which is then used to lookup the possible schemas for that customer, each assigned a schemaID (I know you didn’t guess that one). Remember how we mentioned that you can rename things on the fly? Well, that means we can’t actually store ‘real’ names, but instead have to use aliases. These aliases are stored alongside the customer schema so we can manage those aliases directly as part of the schema. So the schema for a thing is an instance of a schema.
Let me say that again - the schema for a given ‘object’ for a customer is actually a combination of the tenantID
- schema ID + schema alias(es). We have schema for describing a tenant + its known schemas (Metadata) and then each schema has its own schema (Metric). Then for a given type of ‘thing’ for a given company, we store instances of the metadata and each metric. This leads to a schema repository that looks like:
| subject id | schema |
|---|---|
| _fineo-metadata | Metadata.schema |
| _fineo-metric | Metric.schema |
| data production inc. | Metadata.instance |
| n1 | Metric.instance |
| n2222222 | Metric.instance |
Ok, that is going to take some explaining. The Metadata.schema and Metric.schema are actually the following Avro schemas[3]:
record Metadata {
string canonicalName;
union {null, map<array<string>>} canonicalNamesToAliases = null;
}
record Metric{
Metadata metadata;
string metricSchema;
}These schemas are then used to to understand the Metadata and Metric instances we get per customer. Going back to our example of DPI above, your first level Metadata instance will look something like:
{
"canonicalName": "n1",
"canonicalNamesToAliases": {
"n2222222": ["machine1", "machine1b", "machine1c"]
}So the customerId is n1. This customer only has a single schema, with the canonical name n2222222.
However, we might get multiple different device name types that are really the same “thing”. This is useful when you
have devices from different manufacturers that produce different metrics, but are really the same thing.
From there, you can also lookup the schema instance for the device n2222222 (which to the client looks like
they are looking up machine1 or machine1b or machine1c). That will give you something like:
{
"metadata": {
"canonicalName": "n2222222",
"canonicalNamesToAliases" : {
"f1": ["field1"],
"f2": ["field2", "field2b"]
}
},
"metricSchema": "\\ some encoded avro schema based on a BaseRecord \\"
}We have a known set of fields that are included in every record, comprising a BaseRecord and its BaseFields:
record BaseRecord {
BaseFields baseFields;
}
record BaseFields{
string aliasName;
long timestamp;
map<string> unknown_fields;
}For now, its enough to understand that this is the basic building block of an ‘object’ schema. Shortly, we will discuss how its actually used.
Wait. What are you keeping track of?
A machine is actually an instance of a Metric, that has an instance of its own metadata to map canonical field
names, keep track of its own name and then store the schema for the actual customer record. This allows us to
evolve how we define a generic schema for a tenant or metric, as well as evolving how the schema for a given ‘thing’
looks.
Using schema to define schema… and then a big of pile of turtles at the bottom :)
Note that Avro’s standard aliasing because it only applies to records, which means that every field becomes its own record instance, which quickly gets to be a pain to manage and also prevents easy alias logic reuse. I’m not saying you couldn’t do it, it just gets to be a pain (left as an exercise to the reader).
Building schema - modern DDL
The schema for a given field is programmatically built based on what the customer sends us. By using an instance of
the Metadata we can dynamically rename fields without actually changing any underlying data. Eventually, we also want
to do dynamic type conversion and lazy ETL.
Each Metric instance’s metricSchema (I know, the naming is a touch confusing - I’m open to suggestions) is actually
an extension of the BaseRecord. Each event in the platform is expected to have a couple things:
- a timestamp
- a customer specified alias (which we remap to a canonical name)
- some number of unknown fields
Going back to our example of DPI, they brought a new machine online which has a couple of metrics: temperature, pressure and gallons. After connecting it to the platform, we will end up with a record that looks like:
{
"source": "new machine",
"timestamp": "January 12, 2015 10:12:15",
"temperature": "15",
"pressure": "4",
"gallons": "5"
}Which gets remapped via the Fineo ingest pipeline to a simple BaseRecord instance:
{
"alias": "new machine",
"timestamp": "1421057535000",
"unknown_fields": {
"temperature": "15",
"pressure": "4",
"gallons": "5"
}
}The unknown_fields then get stored as simple strings in DynamoDB, which we can read later (through some
smart gymnastics) without having defined any schema or types. At some point later, an admin goes in and
formalizes the schema to types that we talked about. The ‘extended BaseRecord’ and machine Metric
instance then looks like:
{
"metadata": {
"canonicalName": "n2222222",
"canonicalNamesToAliases": {
"f1": ["temperature"],
"f2": ["pressure"],
"f3": ["gallons"]
}
},
"metricSchema" :
"record eBaseRecord {
BaseFields baseFields;
int f1;
long f2;
int f3;
}"
}Since we are backing everything by Avro, we can cache schema until we find it is out of date, and only then request a new one. Further, by storing all the fields by tenant and schema, we have a very high throughput, multi-tenant access that probably doesn’t need much of a cache, which backed by DynamoDB gives us highly scalable schema evolution.
Lazy schema - not your grandmother’s…schema
Part of the power of using a NoSQL store is that we can just stuff in fields without having to touch any DB DDL tools (though our schema management really is just DDL). Since we know the field names, we can then later just query what we expect is in there, and have the database tell us what actually is there.
Our Dynamo extension of the ASR also has support for tracking unknown field names and potential types. When we
receive events that have ‘unknown fields’ we update the unknown fields list for that Metric type in Dynamo and
then write the unknown fields into columns by the customer specified name as simple strings. When customers query for
fields that have not been formalized they have to provide the expected type of the field. We use this expected type
to parse the field and read it into our query engine, but also keep track of the requested type along side the
unknown name.
Thus, without scanning a single row, we know if the fields the customer is requesting could be present. We can also use this type information to suggest to the admin - who does the schema formalization - what type(s) probably describe the field. This makes it wildly easy for admins to easily formalize the schema from the way they already query the data. We could later, as part of our ingest pipeline, also do some simple field parsing on unknown fields to attempt to identify what types it could be.
Nearline to Offline Query
DynamoDB, and other row stores, act really nicely as a near-line data store. You can write data pretty quickly and don’t have to do a lot of expensive work to read relatively large swaths of it back again for smallish analytics (millons of rows).
However, once you come to doing large analytics over a wide time range (10s of millions of rows), these tools start to fall down and more batch-oriented computation over columnar stores starts to look a lot better.
Enter Redshift - columnar store well-suited to doing analytic style queries.
Unfortunately, Redshift isn’t completely dynamic, so we need to have some handle on the types and fields going into it. Thus, we eventually - generally about every month - require that you finally get around to formalizing the schema so we can finish the ingest portion with a large Spark ETL job that does the final step to convert the schematized records from the ingest pipeline into Redshift-ready data.
Naturally, we don’t want to completely rewrite the Dynamo data when we customers formalize the schema - that quickly becomes cost and time prohibitive. Instead, we keep around the old names (remember that alias field?) and query based on the normalized name we generate during schema formalization and the old alias name, in case we have fields that were written with the old, pre-formalization name. We keep different tables for different time ranges (similar, though more manual that doing a TTL in HBase) and age off old tables, eventually letting us limit the fields we query to just the normalized field. Since we know when the data was written - everything has a timestamp - and when the schema was formalized, we can be very specific about which field name we expect.
Enterprise-y extensions
Dynamic schema management and lazy evolution gives users lots of power to manage their data. At Fineo we take security very seriously - every event is monitored and is auditable. Schema changes create their own ‘schema change event’ (which itself has its own schema). So do queries - on dynamic and known fields. Now you can see exactly what data came in and who changed what when. And you can do it all in SQL, so you know its easy.
We also leverage industry-standard, fine-grained, role-based access control. This lets you choose who can write data, make queries, create and trigger alerts and formalize schema.

In conclusion…
As a customer of Fineo you can write almost any data your want, whenever you want at pretty much whatever rate you want. We trust Amazon to handle whatever load you can throw at it (they’ve gotten pretty good) and then load it into our query platform in realtime[4]. You can then immediately query it, without having someone ahead of time figure out the types or complaining when the wrong fields are sent.
Future Work
While this gets you pretty far, we do see somethings that we think customers would find helpful:
- field type prediction
- dynamic field typing, so you can change the type of data
- advanced sanitization and transformation
- missing field alerts
Please let me know in the comments or email me if there is anything else you would want to see!
Fineo is also selecting its early beta customers so please reach out if you are interested in getting involved in our upcoming rollout.
Notes
1. Dynamo Schema Repo
We can actually be a bit lazier here and not read/write with full consistency, instead relying on the mutually compatible evolutionary nature of Avro schema. We should be able to step through old versions to read data from data serialized with an older schema. In fact, we can keep track of which schema number (schema-id) the data was written with and just use that schema to deserialze data.
2. Elastic Beanstalk
Ok, we could actually use AWS Elastic Beanstalk to do a lot of the ops for us in deploying the web service. However, they is still another moving part. It gets us nice separation and ability to evolve schema, but that seemed minor gains right now compared to the overhead of running another service . Of course, as Fineo grows this will not always be the case and the advantage of using a more SOA style architecture will be increasingly compelling.
3. Metric Fields
We also have the ability to ‘hide’ fields associated with a machine. This allows us to do ‘soft deletes’ of the data and then garbage collect them as part of our standard age off process.
4. Realtime
For some definitions of realtime. Currently our ingest pipeline is less than 1 minute, though we have extensions that allow querying on data within tens of milliseconds of ingest. Talk to Jesse if that is something you are interested in.
-----------
Like this sort of stuff? Consider subscribing to the RSS feed.
blog comments powered by Disqus