Intro To Culvert
November 17, 2011 - Seattle, WACulvert is a secondary indexing platform for BigTable, which means it provides everything you need to write indexes and use them to access and well, index your data. Currently Culvert supports HBase and Accumulo, though new adapters are in the pipeline. If you don’t know why we need a secondary indexing platform for BigTable, I recommend checking out my previous post.
I’ll pause while you go and catch up.
…
Ok, at this point I’ll assume that (1) you know what secondary indexing is and (2) you want to know how to actually use Culvert to solve your secondary indexing problems.
Lets start with how you can actually get a Culvert client up and running. Turns out its pretty simple.
We are going to use an example of connecting to an Accumulo Database:
// start configuring how to connect to the instance
Configuration conf = new Configuration();
conf.set(AccumuloConstants.INSTANCE_CLASS_KEY, ZooKeeperInstance.class.getName());
conf.set(AccumuloConstants.INSTANCE_NAME_KEY, INSTANCE_NAME);
// set all your other configuration values
...
// create the database adapter with a configuration
DatabaseAdapter database = new AccumuloDatabaseAdapter();
database.setConf(conf);
// create a client to configure
Client client = new Client(CConfiguration.getDefault());
//setup the client to talk to your database
Client.setDatabase(database, client.getConf());
That wasn’t too bad, right? At this point we’ve got a client to talk to the database. Since you are using Culvert is for indexing, the next thing you would want to do is add an index. Its actually pretty simple programmatically:
// create term-based index: index each of the words in the value, where the
// row key is the word and the row id is stored in the rest of the key
Index index = new TermBasedIndex(INDEX_NAME, database, PRIMARY_TABLE_NAME,
INDEX_TABLE_NAME, COLUMN_FAMILY_TO_INDEX, COLUMN_QUALIFIER_TO_INDEX);
// other index definitions could also be loaded from the configuration
...
// and programmatically add the index to the client's configuration
client.addIndex(index);
Its important to note that each index needs to be given a unique name, otherwise namespace conflicts will occur. But generally this is not a problem and it useful when you want to have more than one index of the same type (eg. You want to do a TermBasedIndex on two different tables, two different fields, two different whatever).
You can also save yourself some effort by setuping your indexes in the configuration – the client will pick these up when it starts and automatically make sure the indexes you specified are used.
Once you have the client setup and all the indexes specified, the next step is to put data in the table. All data is wrapped as the high level Culvert type key and value - a CKeyValue. A CKeyValue is then transformed into the correct key and value for the underlying database. This makes doing an insert very similar to how inserts are done already in a BigTable system:
// build the list of values to insert
List valuesToPut = Lists.newArrayList(new CKeyValue("foo"
.getBytes(), "bar".getBytes(), "baz".getBytes(), "value".getBytes()));
//wrap them in a put
Put put = new Put(valuesToPut);
//and just make the put
client.put(PRIMARY_TABLE, put);
Pretty simple, right? Not only are these items being inserted into the database, Culvert also takes care of all the heavy lifting for you of make sure those values get indexed by all the indexes you have added to the client.
Secondary indexes are only useful if you can actually access the data. Culvert also handles doing this via “Constraints”. A constraint is the way you query the index, it’s the way you get the columns associated with row ids that the index stores and its also the way you can do efficient SQL-like queries.
For those interested, we used the decorator design pattern here to make it really easy to that nesting. Every constraint takes another constraint and some parameters.
Querying your data back out using the indexes is a little bit more complex as you have to build up your constraints but once you pick up the general strategy, it isn’t too bad. Lets start with just doing a simple query of the index looking for any records that have the word “value” in them:
Index c1Index = client.getIndexByName(INDEX_NAME);
Constraint c1Constraint = new RetrieveColumns(new IndexRangeConstraint(
c1Index, new CRange("value".getBytes())), c1Index.getPrimaryTable());
// check the first constraint
SeekingCurrentIterator iter = c1Constraint.getResultIterator();
First, we get the index out of the client that you want to use when querying (to make sure you are searching for the right field). Then you build a constraint to use as a query.
That constraint is actually a nested constraint, describing each step in the process. First you scan the index to get the row ids of the field you are looking for (in this example, rows that the have word “value”) – this is the IndexRangeConstraint. You can basically think of this as a ‘WHERE’ clause where we explicitly specify the index to search for that value. This is because for things like the TermBasedIndex, you would be looking for values in different fields, depending on which index you use – you don’t want to look for email sender names in the content field, right? Most queries are going to start with an index range constraint.
Then once you have an all the row ids, you can go and actually get the rows specified using RetrieveColumns – retrieving all the columns associated with that row id. Its just like you would be doing with indexes all ready, just formalized and prebuilt for you. Makes sense, right?
That is the simple case - you just want to pull values of your table that you have indexed.
Now consider a little bit more complex case – doing an AND between the results of two queries. Now the simple, home rolled solution, is that you load all the left side of the AND into memory, then check to see which values from the right side match up. This is actually pretty bad if you pick the wrong side of the AND to load into memory – you will probably blow out memory and crash your client before getting any result. Culvert takes a different approach - each side of the AND is streamed to the client and only matching values are kept around, so you never have more than the number of matches +2 elements in memory. It looks something like this:
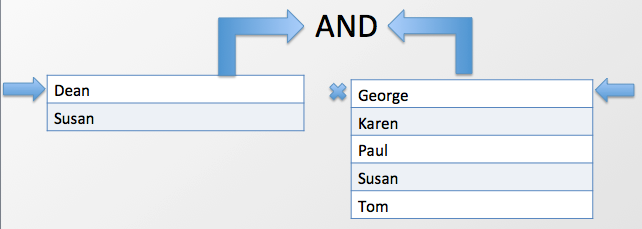
Each side of the AND is streamed back to the AND logic on the client, where we can decide which rows to keep and which rows to discard. Note here that Culvert is leveraging the fact that the BigTable model enforces that from each TableServer or RegionServer will returned ordered results, so all we need to do is make sure we match the right results up. Here is the code to do an index based AND:
Constraint and = new And(c1Constraint, c2Constraint);
iter = and.getResultIterator();
In the beginning lets assume that you already have the Constraints for each side of the AND based on the index you want to search (just like we did before)
Culvert also supports a variety of other SQL-like constructs OR and JOIN. OR works very similarly to AND, just with slightly different logic. JOIN, on the other hand, can be either naïve – just joining two tables – or index based. However, in both cases if the underlying database supports it, the JOIN is actually implemented as a server-side join. This means it is incredibly efficient and powerful. Currently only the HBase adapter supports server-side joins, but Culvert developers are working on extending Accumulo to support this functionality (see ACCUMULO-14).
If you don’t want to use straight Java to interact with the index, Culvert also (soon!) works with Hive. It integrates directly with Hive as just another handle (similar to how the HBase-Hive handler works). When you send an HQL query to Hive, Culvert pulls out the predicates that it can handle and then queries the indexes you have specified via configuration to serve out only the results that Hive will actually use. This means you get huge speedups using Culvert with Hive.
And that is really all there is to using Culvert!
I’m thinking about continuing the Culvert series with a more in-depth look at the underlying architecture - really examining some of core components and how all the pieces fit together. In the mean time, if you are interested in learning about how it works under the hood, you can see the original talk from [Hadoop Summit 2011] (http://www.slideshare.net/jesse_yates/culvert-a-robust-framework-for-secondary-indexing-of-structured-and-unstructured-data)
The code is available on [gituhub] (http://www.github.com/booz-allen-hamilton/culvert). Feel free to check it out, provide feedback, and if you are feeling really generous, contribute some code :)
-----------
Like this sort of stuff? Consider subscribing to the RSS feed.
blog comments powered by Disqus